ディープラーニングによる一般物体認識とビジネス応用<上>画像分類
株式会社Laboro.AI 代表取締役CTO 藤原 弘将
2019.12.7
概 要
このコラムでは、一般物体認識と呼ばれる画像認識の分野を題材に、技術の概要と代表的なデータセットに対する精度を紹介します。さらに、現実の課題を適切に問題設定するために必要な知識を整理することを目的に、ビジネスに応用する際に考えるべき視点についても触れていきます。
このコラムは上下2本編成で、今回は一般物体認識のうち「画像分類」について解説します。
(*本コラムの内容は、『画像ラボ(2019年1月号)』への寄稿論文を抜粋編集したものです。)
目 次
・一般物体認識について
・画像分類の概要
・画像分類の代表的なベンチマークデータと性能
・画像分類の実用化の際の検討ポイント
・画像分類の実用化事例の紹介
・まとめ
一般物体認識について
画像中に写っているものをコンピューターによって認識する研究は、一般物体認識と呼ばれ、ディープラーニングの登場以前から広く行われてきました。人手で設計した特徴量(Joint HOGやJoint Harr-likeなど)に対して、機械学習手法(サポートベクタマシンやブースティングなど)を適用することが一般的でした。ただ、このような従来手法は精度に限界があり、実用化まで至った例は多くありませんでした。その後、ディープラーニング技術の登場と発展に伴い、画像データを直接ディープラーニングに入力して、特徴抽出と識別を同時に最適化することが一般的になり、精度が劇的に向上しました。
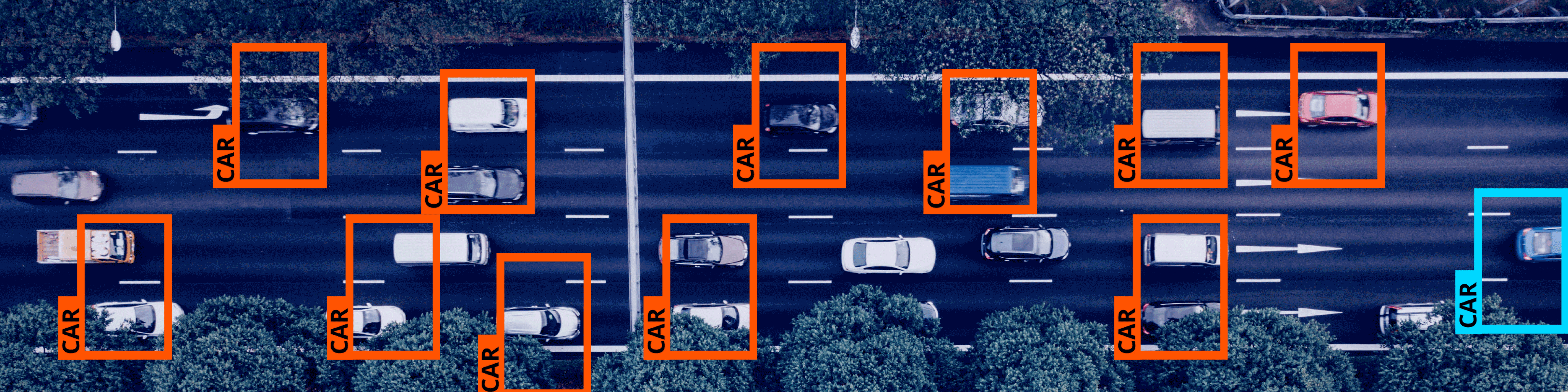
一般物体認識の問題は、認識結果を最終的にどのような形式で出力するかによって、(a)分類(b)物体検出(c)セマンティックセグメンテーションの3つに大別され、この順に難易度は上がっていきます。このコラムでは、その内(a)分類と(b)物体検出について解説します。

なお、一般物体認識は、教師あり学習であり、人手で設計した認識対象に基づいて学習データ及び教師ラベルを準備する必要があります。「一般」という言葉は、アルゴリズム自体が認識対象に非依存なことを指し、データを変えることで認識対象をコントロールできることを意味しています。学習データに含まれない対象は原理的に認識できず、何を認識すべきかを自動的に発見できるわけではないことには注意が必要です。一方、アルゴリズム自体を特定の対象に特化して設計することで、精度を上げることは可能で、例えば、人間の顔の認識の際は、目や口などのパーツの存在を前提として、それらを同時に認識することで精度を上げる技術が存在します。
画像分類の概要
画像の分類とは、画像に写っている物体のカテゴリ(クラスと呼ばれる)を認識結果として出力する問題です。その物体が画像中のどこにあるかは判別しません。分類対象のカテゴリは、前述のように、問題設定の一部として人手で設計する必要があります。一枚の画像が必ず一つのカテゴリに紐づく場合(=識別)と、1枚の画像に複数カテゴリが対応しうる場合(=タグ付け)がありますが、基本的なニューラルネットワークの構成は同様で、最終的な出力層の形式と誤差関数が異なります。画像分類のためのニューラルネットワークのモデルは、物体検知等の問題設定向けのモデルの構成要素(バックボーンと呼ばれる)として使われるため、とても重要です。

ニューラルネットワークのその高い性能を世に知らしめて、爆発的な普及のきっかけとなったのが、この画像分類の問題でした。2010年から2017年まで実施されていたILSVRC(ImageNet Large-scale Visual Recognition Challenge)での画像分類のコンペティション(100万枚以上の学習データを用いて1,000クラスを識別)では、2010年と2011年の優勝チームの精度はそれぞれ71.8%と74.2%(Top-5正解率)でした。ところが、2012年にトロント大学のジェフリー・ヒントン教授らのチームが開発したCNNに基づく画像認識モデルAlexNetは、精度84.7%を達成し、一気に10ポイント以上の精度改善を成し遂げました。その後、ニューラルネットワークの構造も進化し、2015年にはMicrosoftが開発したResNetと呼ばれるモデルが96.4%、ILSVRCの最終年であった2017年にはオックスフォード大学と中国の自動運転スタートアップのチームが97.7%の精度を達成しました。この精度は人間の精度を超えているとされ、2011年時点では実用的な精度を出すのが難しいと思われていた問題を、わずか6年の中に解決済みの問題にしてしまいました。
CNNによる画像分類が従来手法に比べて高い精度を達成した要因の一つとして、特量抽出の自動化があると言われています。従来の画像処理手法では、機械学習部分はデータから最適化しますが、特徴抽出部分の設計は人であり、性能向上のボトルネックとなっていました。CNNでは、入力として(正規化等の前処理はするものの)生の画像に近いデータを直接入力して、CNNを構成するフィルタの重み自体をデータから推定します。特徴抽出と機械学習部分を一体で最適化しているとも考えることができるため、特徴量自体を問題に合わせて最適な形で学習していると言えます。
CNNによる画像認識が登場した当初は、一つのモデルで使用されるCNNの層数は多くなく、初期の代表的なモデルであるAlexNet は5層でした。その後、層数を増やすことが精度向上に効果的なことが明らかになり、19層のVGGや、最大152層のResNetなど総数が増加し、ネットワークの構成も複雑化しています。同時に、複雑なネットワークの層をショートカットする接続を導入したSkip Connectionや、CNNの層ごとに入力される値を正規化するBatchNormalizationなどがあります。また、ネットワーク構成自体もニューラルネットワークで最適化するNAS(Neural Architecture Search)と呼ばれる技術も提案されており、Googleがクラウドで提供する画像分類サービスであるGoogle Cloud AutoML Visionで導入されています。
画像分類の代表的なベンチマークデータと性能
画像分類の研究のための代表的なデータセットとして、ImageNetがあります。ImageNetは、Webから収集した1,400枚もの画像に2万クラス以上のアノテーションを付与した大規模なデータセットです。前述のILSVRCは、ImageNetの一部(1,000カテゴリ、130万枚)をデータとして用いたコンペティションで、画像分類研究での代表的なコンペティションとして技術の発展に大きく貢献しました。ILSVRC用のImageNetデータの一部がこちらです。

ILSVRC用のデータで学習したニューラルネットワークの重みは、画像分類のモデル自体が、物体検知等の他タスク用のモデルの構成要素であることも相まって、画像分類に限らず多くの分野で転移学習の元となる重みとして使われています。
ILSVRCの精度は、最終年である2017年の優勝モデルで、Top-5正解率97.7%と非常に高い精度を達成しています(ただしこれはモデルアンサンブルの結果)。学習済みの重みが広く公開されている単一モデルでは、例えばディープラーニングフレームワークの一種であるKerasに付属するモデルで、NasNetが96.0%、Inception ResNet V2が95.3%、Xceptionが94.5%の精度です。人間のTop-5正解率が94.4%程度とされており、人間を上回る精度を達成しています。
画像分類の実用化の際の検討ポイント
画像分類技術は、認識対象の場所が特定できないという問題点はあるものの、画像全体に一つのものが写っているような応用や、問題を組み換えて画像全体からの判断に落とし込めるような応用では、問題の入出力の設計としては、適用することができます。
その上で、最初に検討すべきなのは、問題設定の適切さと期待される精度です。確かにImageNetのデータに対しては人間を上回る精度を達成していますが、これはあくまで訓練れていない人間との比較であり、私の過去の経験では、訓練された人間レベルには届かない場合が多いのが実際です。訓練された専門家と同じ精度が出ないと実用化にできない領域(例えばクリティカルな判断で、人間を計算機に完全に置き換えたい場合など)では、未だ導入は難しい場合が多くあります。また、単純に画像に写っているものを判別する以上の知的な処理が必要な場合、例えば本来画像に写っているはずが写っていないものを社会常識に基づいて判断する場合などでは、精度はImageNetの結果等から類推するより大きく低下します。
次に検討すべきは、処理環境と速度です。大規模なサーバー環境で実行できる場合でも、一つのGPUで1秒間に30枚程度の処理速度です。単位時間内に実際に認識が必要な枚数と実行可能な環境(サーバー上なのかエッジでの実行なのか)によっては、そもそもディープラーニングでの画像分類が向かない場合もあり得ます。
画像分類の実用化事例の紹介
(株)LIFULLは、不動産ポータルLIFULL HOME’Sにおいて、物件写真の自動分類機能を導入しました。具体的には、不動産会社等の担当者が物件写真をサイトにアップロードする際に写真の種別(外観なのか、キッチンなのかなど)を自動的に判別することでデータ入力をサポートするものです。十数枚の物件画像を登録するのにかかる時間が、手作業で40〜50秒かかっていたのに対し、10〜12秒に短縮されました。Googleの画像分類クラウドサービスであるCloud AutoML Visionを使用して構築され、Google Cloud Platform(GCP)上で運用されています。
クックパッド(株)は、日々の料理の写真やレシピを記録するスマートフォンアプリ「料理きろく」に料理画像認識機能を搭載しました。機械学習技術により、スマートフォンに保存された画像から、料理が写っている写真を撮るだけで自動的に料理の記録が残されます。画像に料理が含まれているかどうかを、2カテゴリの分類問題として扱い、検証用データに対して精度98%、再現率96%の精度を実現しています。機械学習技術は自社開発で、AWS上で運用されています。
(株)村上開明堂は、自動車用バックミラーの検品を画像分類技術で効率化しました。生産ライン上のミラーの画像に対して、キズ、ほこりなどの15種類の不具合カテゴリを識別して、人間の検品作業の手助けをするというものです。機械学習の判断の信頼度をもとに、OK、NG、人間に任せるの3パターンの判断をします。検証用データに対して誤りが2%以内に抑えられました。
国立がん研究センターと理化学研究所は、内視鏡画像からの早期胃がん発見の問題に画像分類技術を用いています。胃がんは内視鏡画像の一部に存在し、その場所自体を検出する必要があるので、本来であれば後述の物体検出やセマンティックセグメンテーションの問題ですが、この事例では内視鏡画像を上下224ピクセルのパッチに切り出して、パッチごとにがんの有無及び種類を分類する問題に落とし込みました。パッチごとに「がん」画像を正しく「がん」と判定する精度が80%、正常画像を正しく正常と判定する精度が94.8%でした。

まとめ
今回は一般物体認識のうち画像分類にフォーカスを置き、その概要と実用化の際のポイント、また具体的な実用化例を紹介しました。次回は、今後のビジネス活用が見込まれつつ発展余地の大きい画像認識の分野、「物体検出」について解説していきます。
続けて読む
▶︎ディープラーニングによる一般物体認識とビジネス応用<下>物体検出
コラム執筆者
代表取締役CTO 藤原 弘将
京都大学大学院修了 博士(情報学)。2007年、産業技術総合研究所にパーマネント型の研究員として入所。機械学習を用いた音声/音楽の自動理解の研究に従事。開発した特許技術を様々な企業にライセンス提供し、ライセンス先企業の技術顧問も務める。2012年、ボストンコンサルティンググループに入社。ビッグデータ活用領域を中心に多数業界・テーマのプロジェクトに従事。AI系のスタートアップ企業を経て、2016年に株式会社Laboro.AIを創業。代表取締役CTOとして技術開発をリード。
その他の執筆コラム
・AI精度に不可欠な評価基準の検討
・AIで「やりたいこと」とデータは、両輪で議論する
・“AI”のギャップが、ビジネスへの導入を妨げる
・AIは不完全。本当に必要な「AI人材」の役割とは
・ディープラーニングによる一般物体認識とビジネス応用<下>物体検出



