
再確認、ニューラルネットワークの仕組みと分類の基本
2023.9.19公開 2024.4.1更新
株式会社Laboro.AI リードマーケター 熊谷勇一
概 要
ニューラルネットワークはディープラーニングの根本的なモデルであり、現在のAI・機械学習の基盤とも言えます。その仕組みや発生し得る問題と解決方法、種類など、基本を解説します。
目 次
・ニューラルネットワークとは
・ニューラルネットワークの仕組み
・入力層、出力層、隠れ層の3種類で構成
・ニューラルネットワークの学習手法
・Dropout法
・確率的勾配降下法
・誤差逆伝播法
・ニューラルネットワークの種類
・ディープニューラルネットワーク(DNN)
・畳み込みニューラルネットワーク(CNN)
・再帰的ニューラルネットワーク(RNN)
・敵対的生成ネットワーク(GAN)
・オートエンコーダ(自己符号化器)
・関連して知っておきたい「分類」と「回帰」
・分類問題への適用
・回帰問題への適用
・知らなくても使えるが、知った方が広がる
ニューラルネットワークとは
ニューラルネットワーク(neural network)とは、人間の脳の中の構造を模した学習モデルのことです。人間の脳にはニューロンと呼ばれる神経細胞が何十億個も張りめぐらされていて、互いに結び付いて神経回路というネットワークを構成しています。人間が何かの情報を感知すると、ニューロンに電気信号が伝わり、ネットワーク内をどのように伝わっていくかによって、人間はパターンを認識しています。ニューラルネットワークはこのニューロンの特徴を再現しようとする手法です。
ニューラルネットワークはデータのルールやパターンを自動的に学習する機械学習の一つであり、ニューラルネットワークを多層にしたものがディープラーニングです。
出典:日本ディープラーニング協会監修『ディープラーニングG検定公式テキスト』第2版
ディープラーニングについてはこちらもご覧ください。
AIと機械学習、ディープラーニング(深層学習)の違いとは
ニューラルネットワークの仕組み
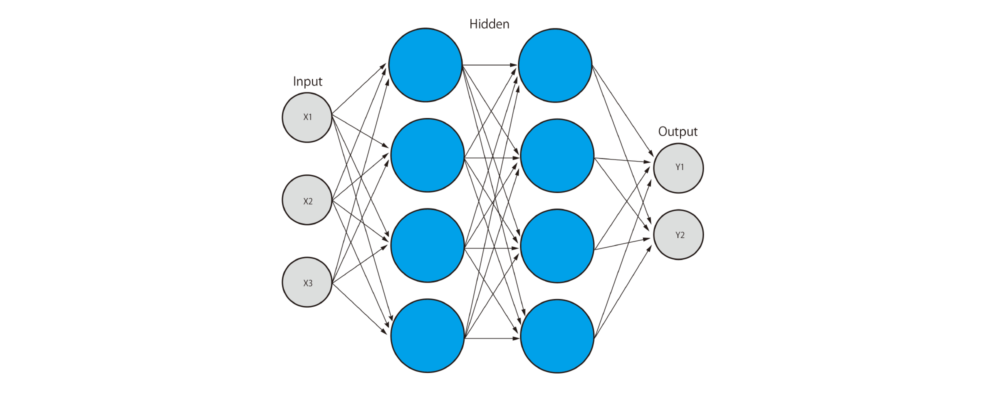
入力層、出力層、隠れ層の3種類で構成
ニューラルネットワークは、入力を受け取る部分である入力層、出力する部分である出力層、中間層(隠れ層とも呼ばれる、入力層と出力層の間にある層)の三つの層から構成されています。入力層にデータを入力して、データの指標で特徴量を入力し、出力層にニューロンを入力することで最終結果の算出が可能です。
入力層と出力層だけで構成されているモデルは単純パーセプトロンと呼ばれます。初めて開発されたパーセプトロンは、この隠れ層がない単純パーセプトロンでした。これには線形分離不可能な問題を解決できないという欠点がありました。しかしその後、入力層と出力層の間に隠れ層を追加し、ネットワーク全体の表現力が向上し、非線形分類など複雑な問題も解決できるようになりました。このモデルは多層パーセプトロンと呼ばれています。
Udemyメディア「ニューラルネットワークとは?人工知能の基本を初心者向けに解説!」
ニューラルネットワークの学習手法
Dropout法
Dropoutはニューラルネットワークの過学習を防ぐために提案された手法で、一定の確率でランダムにニューロンを無視して学習を進める方法の一種です。
過学習とは、訓練データの正答率が 徐々に上がっていった際、テストデータの誤差が 減少が止まり、また増加し始めてしまう状態を指します。ニューラルネットワークの構造が複雑化していくにつれて、ニューロンの重みは訓練データセットに最適化されていってしまいます。汎化作用が働かず、一つひとつのデータを暗記していくように、訓練データセットにしか使えない融通の効かないモデルとなってしまうのです。
ニューラルネットワークの過学習を防ぐ方法は四つあります。
・訓練データセットを増やす
・モデルの複雑性を減らす
・Early Stopping(早期終了)
・モデルの複雑さにペナルティーを与える(正則化)
Dropoutはこの正則化の一つです。正則化とは、モデルが複雑な形状になった場合にペナルティを設けることで、モデルをなるべくシンプルな形状に保つという方法の一つです。
ダイヤモンドオンライン「ディープラーニングを支える黒魔術「ドロップアウト」」
DeepAge「Dropout:ディープラーニングの火付け役、単純な方法で過学習を防ぐ」
確率的勾配降下法
最急降下法の一種で、ランダムなデータ一つのみで勾配を求め、パラメータ更新をしていく作業をデータの数だけ行う方法です。最急降下法ではすべてのデータを毎回使用するため、全体ではなく局所的な最適解に陥ってしまう可能性がありますが、確率的勾配降下法では局所解に陥っても次のデータはランダムに選ばれるため、脱出が可能という利点があります。
zero to one「確率的勾配降下法」
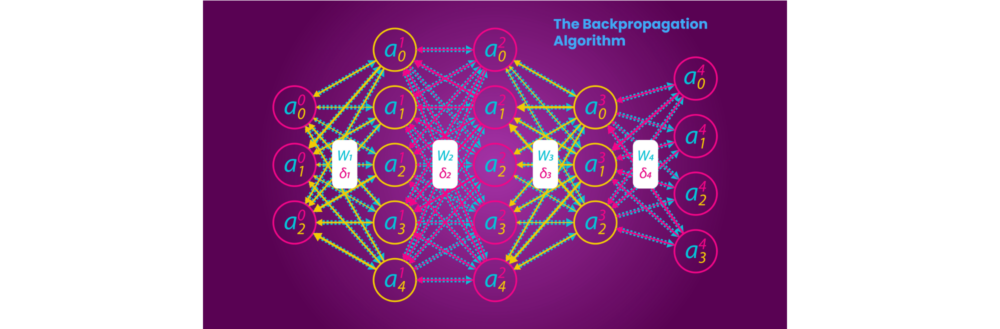
誤差逆伝播法
誤差逆伝播法(Back Propagation)は、多層パーセプトロンの学習に使われる学習アルゴリズムです。ある学習データが与えられたとき、多層パーセプトロンの出力が学習データと一致するように各層の間の重みを修正するという学習法です。多層パーセプトロンは誤差逆伝播法によって教師あり学習を行い、パターン識別や関数の近似などに用いられます。
九州工業大学大学院生命体工学研究科人間知能システム工学専攻古川研究室「誤差逆伝播法(BP:Backpropagation)」
ニューラルネットワークの種類
ディープニューラルネットワーク(DNN)
ディープニューラルネットワーク(Deep Neural Network、DNN)とは、ニューラルネットワークをディープラーニングに対応させて4層以上に層を深くしたもののことです。ディープラーニング登場以前は、隠れ層を2以上に増やして合計4層以上のネットワークにすると、精度が出なくなる問題がありました。
しかし2006年以降、ディープラーニングの手法が考えられてから、その問題が克服されました。さらに2010年ごろから、ビッグデータがより容易に扱えるようになったことや、GPU(Graphics Processing Unit、画像処理装置)などのコンピュータ性能の大幅な向上が重なったことがきっかけとなり、今では高度なDNNを比較的容易に実行できるようになりました。
@IT「ディープニューラルネットワーク(DNN:Deep Neural Network)とは?」
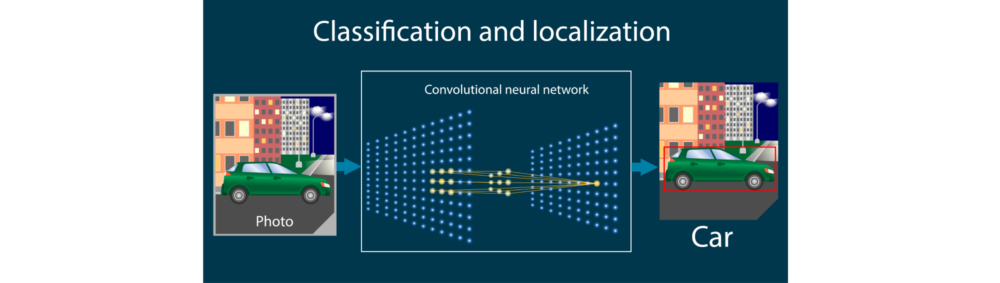
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワーク(Convolution Neural Network、CNN)とは、AIが画像分析を行うための学習手法の一つで、一部が見えにくくなっているような画像でも解析することができます。畳み込み層とプーリング層という二つの層を含む構造を持つ、DNNの一つです。
分析する画像が入力層に読み込まれた後、このデータをくまなくスキャンし、データの特徴(勾配、凹凸など)を抽出するために使われるのがフィルタです。抽出された特徴データは畳み込み層に送られ、そこでさらに特徴の凝縮されたデータが作成されます。
畳み込み層で作成されたデータはプーリング層で集約します。例えば最大プーリングという集約方法をとる場合、各ユニット(領域)のピクセルを比較し、その中の最大値をそのユニットの特徴量とします。
出力では、プーリング層のユニットすべてを全結合し、計算結果を利用して、フィルタ、重み、バイアス(モデルとデータのズレ)を更新していきます。
Udemyメディア「畳み込みニューラルネットワークとは?手順も丁寧に解説」
再帰的ニューラルネットワーク(RNN)
画像処理に強いCNNに対して、自然言語処理に使われることが多いのが再帰的ニューラルネットワーク(Recurrent Neural Network、RNN)で、こちらもDNNの一種です。「再帰的」とは一種の「ループ」で、例えば「ニワトリが卵を生む」「卵からニワトリが生まれる」という二つの現象が延々と繰り返される状態は、再帰的と呼ばれます。
プログラミングの世界では、実行中のコードがそのコードの中で再び呼び出される処理のことを意味します。これをニューラルネットワークに応用すると「前のネットワークの計算が今のネットワークの計算の元になり、繰り返しながら情報が増えていく」という再帰的なニューラルネットワークになります。
この特徴が自然言語処理に役立ちます。言葉では、前の文章が今の文章に影響を与え、文脈次第で意味が変わることが当たり前に起きます。文章の並び順やつながりが非常に重要な意味を持つため「前の意味を踏まえて今の意味を考える」というプロセスが非常に重要であり、RNNと相性が良いのです。
ビジネス+IT「再帰的ニューラルネットワークとは?自然言語処理に強いアルゴリズムの仕組み」
敵対的生成ネットワーク(GAN)
画像分野での深層生成モデルとして話題になった一つが、GAN(Generative Adversarial Network、敵対的生成ネットワーク)です。入力として潜在空間のランダムベクトルを受け取り、画像を生成して出力する「ジェネレータ」と、入力として受け取った画像が本物か(ジェネレータが生成した)偽物かを予測して出力する「ディスクリミネータ」と言う二つのネットワークから成ります。
ジェネレータはディスクリミネータが間違えるような偽物画像を作るように学習していき、ディスクリミネータは偽物をきちんと見抜けるように学習していきます。つまり、ジェネレータとディスクリミネータを競い合わせることで、本物と見分けのつかない新しい画像を作り出すことを狙ったものです。
日本ディープラーニング協会監修『ディープラーニングG検定公式テキスト』第2版
オートエンコーダ(自己符号化器)
オートエンコーダ(自己符号化器、autoencoder)とは、ニューラルネットワークを利用した教師なし機械学習の手法の一つです。次元削減や特徴抽出を目的に登場しましたが、近年では生成モデルとしても用いられています。
オートエンコーダは、入力データと一致するデータを出力することを目的とする学習法です。オートエンコーダのネットワークは、入力したデータの次元数(ノード数)をいったん下げ、再び戻して出力するという構造になっています。
このため、入力から出力への単なるコピーは不可能です。オートエンコーダの学習過程では、入出力が一致するように各エッジの重みを調整していきます。この学習を通して、データの中から復元のために必要となる重要な情報だけを抽出し、それらから効率的に元のデータを生成するネットワークが形成されます。
こうしてオートエンコーダの前半部分は次元削減、特徴抽出の機能を持ち、エンコーダとも呼ばれます。後半部分は低次元の情報をソースとするデータ生成機能を持つようになり、デコーダとも呼ばれます。
MathWorks「オートエンコーダ(自己符号化器)とは」
関連して知っておきたい「分類」と「回帰」
ニューラルネットワークはディープラーニングの根本的なモデルであり、そのディープラーニングは分類問題と回帰問題でもよく使われます。
分類問題への適用
分類問題には例えば、犬と猫の画像を推論することや、手書きの数字をどの数字に識別することなどがあります。言い換えれば、分布データをどこかで線引きして分類する問題であり、異常データと正常データを見分けることにも使えます。その際、データの分布が一次関数で境界を近似できるような簡単なものであればよいですが、データがバラバラに分布していて法則性を見つけるのが難しいことが少なくありません。そうした複雑な関数近似をしなければならない場合に活用されるのが、ディープラーニングなのです。
出典:ビジネス+IT「ニューラルネットワークの基礎解説:仕組みや機械学習・ディープラーニングとの関係は」
回帰問題への適用
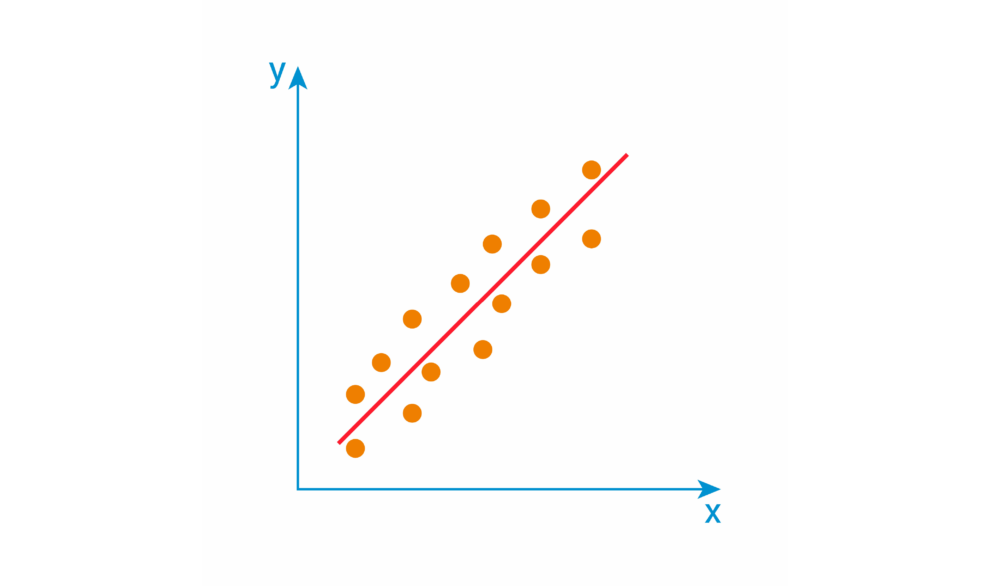
回帰の主な目的は、連続する値の傾向を基に予測をすることです。例えば、企業が商品やサービスの広告費用の増額を検討する際に、「広告費を増やすことでどのくらいの売り上げを見込めるか」という売上予測をすることがあります。下の画像のように、例えばx軸に広告費、y軸に売り上げを取って、傾向となる一次関数を見いだすことです。
回帰分析は、結果となる数値と要因となる数値の関係を調べ、それぞれの関係を明らかにする統計的手法です。 このとき、要因となる数値(上の例の場合、広告費)を「説明変数」、結果となる数値(同、売り上げ)を「目的変数」と呼びます。さらに、説明変数が一つの場合を「単回帰分析」、複数の場合を「重回帰分析」と言います。説明変数の種類が少ない場合は手計算で傾向の関数を得られるかもしれません。しかし説明変数の数が増えていくと困難になるため、ここでもディープラーニングが活用されます。
出典:総務省統計局「高等学校における「情報II」のためのデータサイエンス・データ解析入門」
売上(需要)予測についてはこちらもご覧ください。
需要予測AIよ、需要は予測するものでなく作るものだ。
知らなくても使えるが、知った方が広がる
ChatGPTや画像生成AIなど、ニューラルネットワークを基にしたサービスは数多く生まれ、パソコンやスマホと同様に、動く仕組みが分からずとも使い倒せるようになってきています。仕組みを完全に理解してから使用するよりは、どんどん使用しつつ、仕組みも一つひとつ理解していく方法が、総合的な理解には有効でしょう。そして特に、AIのビジネス活用を考えたとき、仕組みが分かっていればビジネス活用の可能性を広げられたり、導入の見極めができたりしやすくなるのは間違いありません。
さらに、ビジネスのためのAI開発に当たっては、どのようなAI開発をすべきかがなんとなく見当がついたとしても、それが本当に最適な方法なのかどうかは一人では分かりません。AI開発をご検討の際はぜひ、ビジネスとAIの両方を熟知した弊社のソリューションデザイナにご相談ください。議論を通して本当の課題を見極めた上で、ビジネスの成功という目的に合う最適なAIやその開発の在り方を提案いたします。



