
物体検出モデル、M2Detとは
2020.3.3
株式会社Laboro.AI 機械学習エンジニア 胥 徳文
概 要
M2Detは、AI技術の国際的なカンファレンスAAAI-19(The Thirty-Third AAAI Conference on Artificial Intelligence 2019)で北京大学、アリババ、テンプル大学の合同チームにより発表された物体検出技術です。このコラムでは、M2Detの論文および実装について解説していきます。
目 次
・M2Detの概要
・M2Detのアルゴリズムの概要
・M2DetのBackbone
・M2DetのFeature Pyramid
・M2DetのPrediction Layer
・M2DetのLoss FunctionとLearning Rate
・まとめ
M2Detの概要
M2Detを説明するにあたって、まず詳しい技術解説に入る前にその概要から紹介していきましょう。
以下の図1は、M2Detと画像検出の領域でよく用いられる他の技術との性能比較図です。横軸が処理時間を、縦軸が検出精度を表しており、左上にいくほど高速かつ高精度であることを意味します。水色の★マークがM2Detで、RetinaNetやRefineDet、SSD、YOLOなどの既存手法よりも性能が高いことがわかります。
ただし、昨年弊社内で実用化を目指して何度かトライしてみた結果、論文と公開されているソースコードが大きく異なることなどに起因して、現状では高精度の結果を残すことができていません。今回はM2Detの実装内容の解説とともに、論文とソースコードの差異などもピックアップして仕組みを解説していきます。

M2Detのアルゴリズムの概要
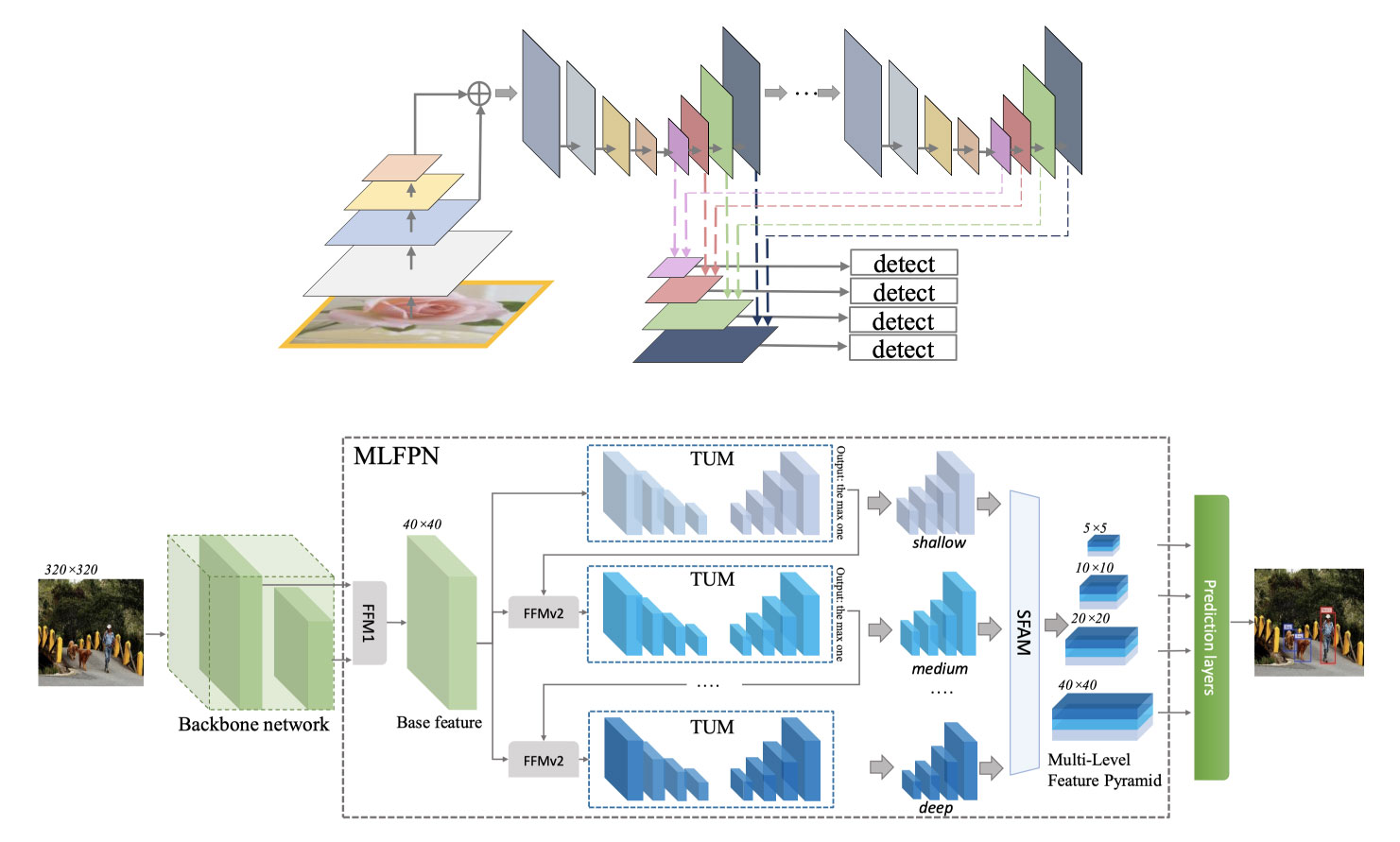
では、M2Detはどのような仕組みで動いているのでしょうか。それを読み解くにあたって、まずはアルゴリズムの構成を解説していきます。以下の図2はM2Detの構成を示したものです。大別するとBackbone・Multi-Level Feature Pyramid Network (MLFPN)・Prediction Layerで構成されていることが分かるかと思います。
以下では、
・Backbone Network
・Feature Pyramid
− Feature Fusion Module(FFM)
− Thinned U-Shape Modules(TUMs)
− Scale-wise Feature Aggregation Module (SFAM)
・Prediction Layer
とそれぞれ順を追って解説していきます。
M2DetのBackbone
まず、M2DetのBackboneについてです。
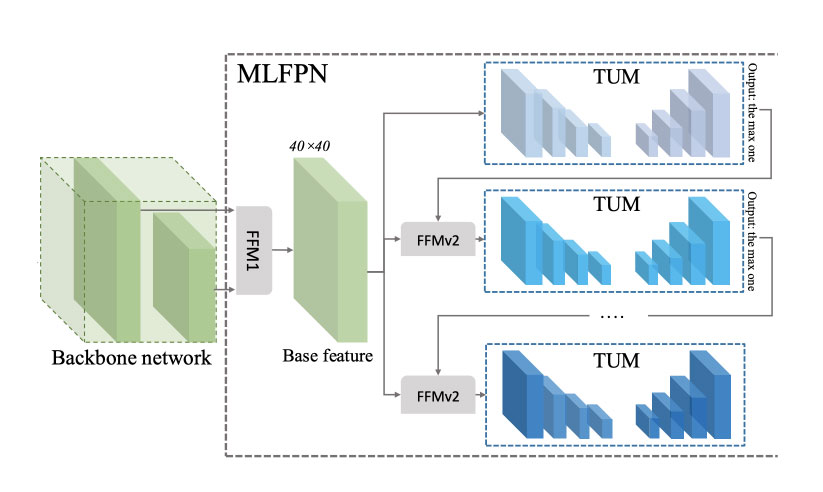
M2Detの論文では、VGGとResNet の2種類のBackboneを実験しています。入力画像サイズをそれぞれ320×320px、512×512px、800×800pxに設定した際の各モデルの精度は下表1の通りです。1秒間あたり何枚の画像を処理できるかの性能を示すFPS(Frames per second)の値についてはVGG-16のBackboneを選択したモデルの性能が良いことがわかります。一方、精度面について同じ画像の入力サイズが同じ場合の結果を比較すると、ResNet-101をBackboneに利用したモデルが最も良い結果を生んでいます。
M2Detの著者実装(layers/nn_utils.py 122-130行目) において、Backboneの呼び出しは、設定ファイル中の値「backbone_name」 から設定できます。なお、Backboneの種類としてVGG16、ResNet50、ResNet101のいずれかを選択できます。
VGG Backbone
M2DetのVGG Backbornの著者実装(layers/nn_utils.py 100-120行目)は、SSDの非公式PyTorch実装のひとつである ssd.pytorch のコード(ssd.py 124-146行目)を流用する形で実装されています。ssd.pytorchにおけるVGG16の実装は、PyTorchの公式ライブラリであるtorchvisionのコードtorchvision/models/vgg.pyを拡張実装したもので、VGG16 (batch_norm なし) の最後のAvgPool層とFC層に代わり、MaxPool層(ソースコード中の変数pool5)、ReLU付きDilated畳み込み層(conv6)、ReLU付き1×1畳み込み層(conv7)を加えた構成になっています。これによりVGG Backbone全体では35層(ReLU層も1層とカウントした場合)で構成されます。
ResNet Backbone
M2DetのResNet Backborn (layers/resnet.py 101-111行目)もVGG同様に、torchvisionのコード torchvision/models/resnet.pyをベースにしており、必要な部分のみを抜き出した形で実装しています。しかし論文には書かれていませんが、表2のLayer3の層がオリジナルのResNetとは異なりstrideが2から1に変更されています。変更の結果、layer3とlayer4の出力サイズが2倍になりますが、これは後述するM2DetのFeature Pyramidで ResNetのlayer2(or layer3)とlayer4の出力を利用できるようにするためです。

M2DetのFeature Pyramid
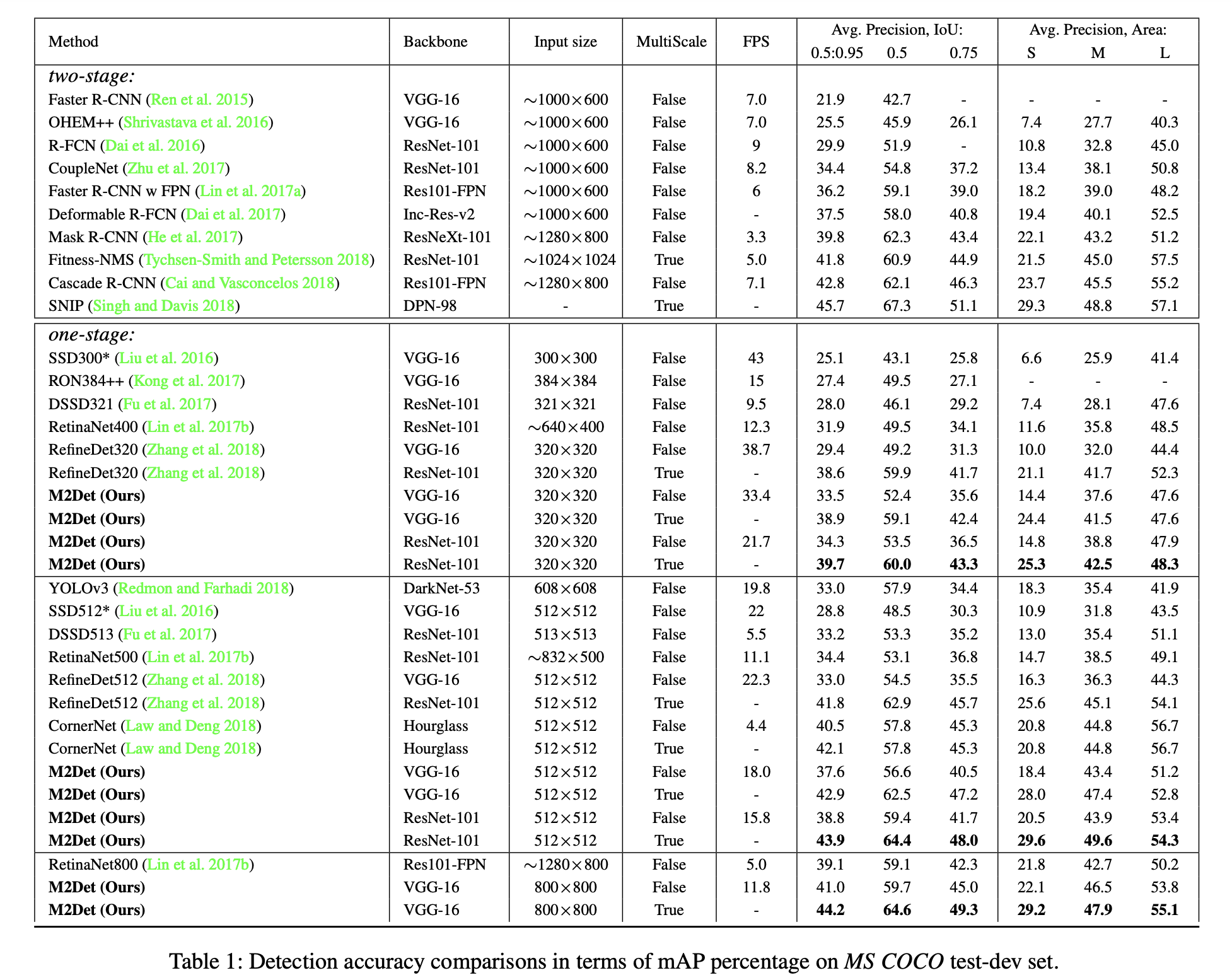
M2Detの特徴の一つは、Multi-Level Feature Pyramid Network(MLFPN)を提案している点です。
MLFPNは、はじめにBackboneの出力をFeature Fusion Module(FFM)で処理しBase Featureを作成します。論文では2種類の特徴マップを統合して一つの特徴マップを生成する処理をFFMと呼んでいます。しかし下図3の通りM2DetではFFMの処理が複数回出てくるため、Backboneに近い方の処理をFFMv1、あとで処理する方をFFMv2と呼び分けています。
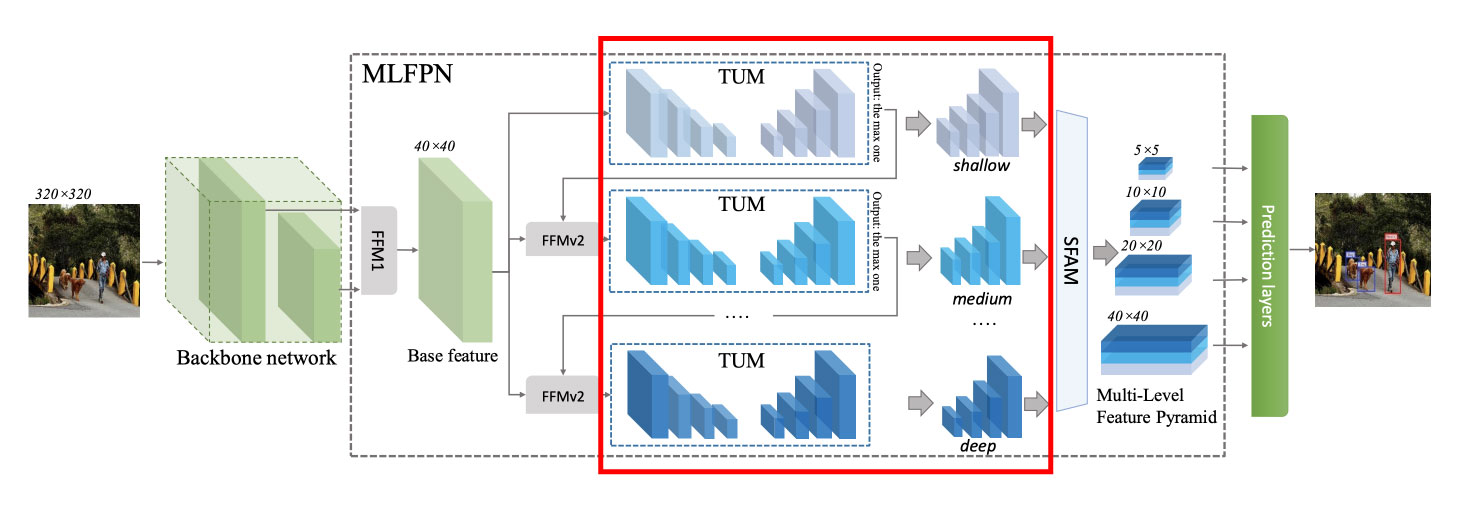
FFMv1で作られたBase FeatureはFFMv2を経由してTUM(Thinned U-shape Module; マルチスケールな特徴マップを作成する役割を持つモジュール)へ渡されます。このTUMは複数が連結した構造になっており、2つ目以降はFFMv2の出力結果を入力とします。さらにSFAM(Scale-wise Feature Aggregation Module; スケールごとの特徴マップを結合し、Feature Pyramidを生成するモジュール)を経由して、最終的に複数の解像度の特徴マップから構成されるMulti-Level Feature Mapとして出力されます。
FFMv1~Base Feature
ここからは、MLFPN上で行われる処理の流れを、モジュールごとに分けて解説します。まずはFFMv1でベースとなる特徴マップであるBase featureを作成する処理について記載します。
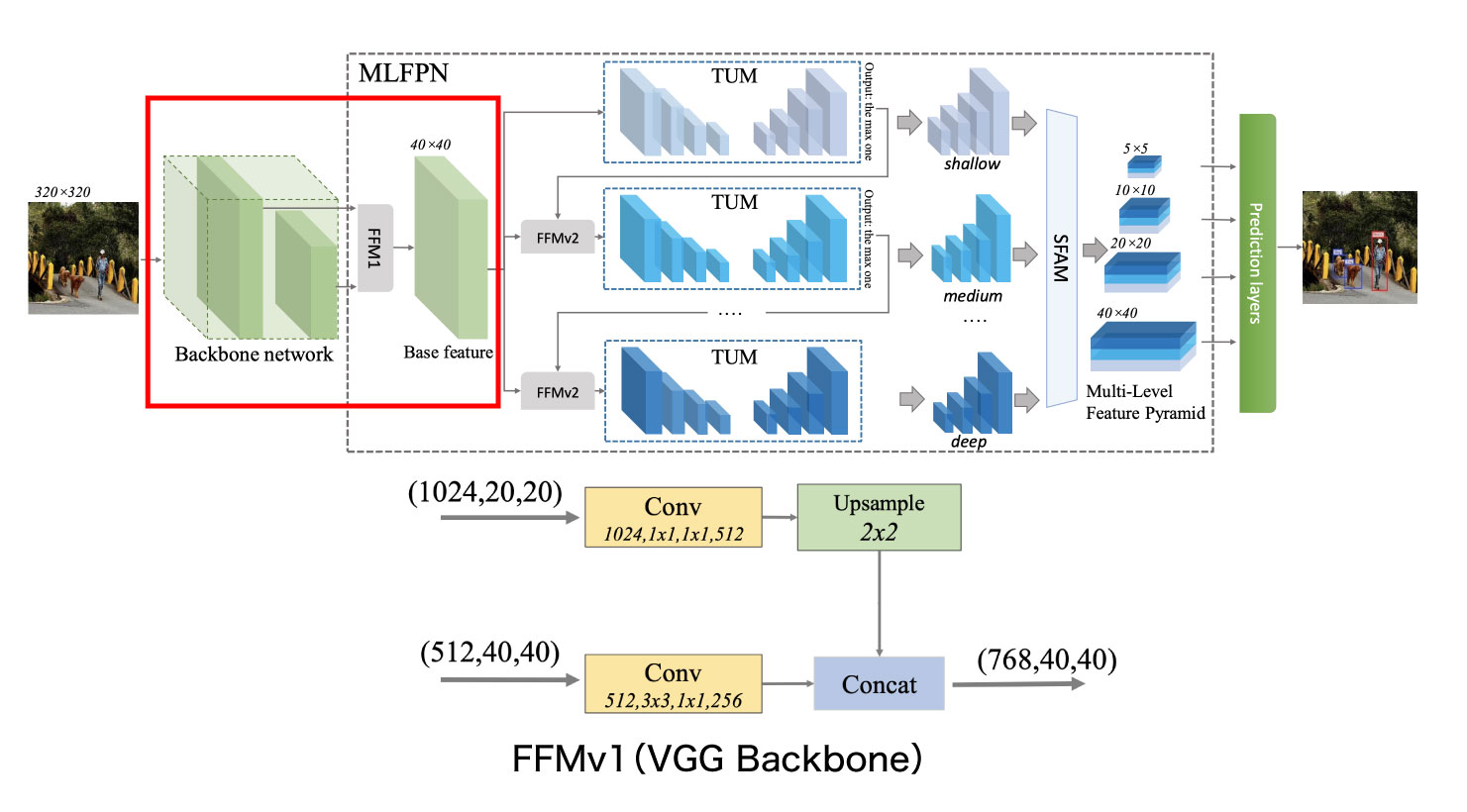
FFMv1では、Backbone中の特定の2つの層を取り出して結合することでBase Featureを生成します(下図4。著者実装中では m2det.py 72-73行目 および 103-113行目)。例えばVGG Backboneの場合は、Backbone側の(最初を0番目と数えて)22番目と34番目の層の出力を結合してBase Featureが作成されます(configs/m2det320_vgg.py 9行目)。同様に、ResNet Backboneを使用する場合は、表2のLayer2(or Layer3)とLayer4の出力層が結合されます(configs/m2det320_resnet101.py 9行目)。
具体的には、Backboneの2つのfeature layerをそれぞれに畳み込み層に通した後に、小さいサイズの特徴マップを大きいサイズの特徴マップにアップサンプリングし連結するという処理が行われます。この際、留意する必要があるのが画像のチャネルサイズです。Backboneによって畳み込み層への入力チャネル サイズは異なるため、これをモデル構築ファイル本体(m2det.py 63-73行目)のハードコーディングされた2つのパラメーター「shallow_in・deep_in」でコントロールしています。
VGG backboneの場合は、浅い層のチャネルサイズが512、深い層のチャネルサイズが1024であるため「shallow_in=512、deep_in=1024」に設定されています。ResNet backboneの場合、layer2とlayer4を利用する前提で「shallow_in=512、deep_in=2048」と設定されています。もしも layer3とlayer4の出力を利用したい場合にはここを「shallow_in=1024、deep_in=2048」のように変更することが必要です。
畳み込み層からの出力チャネル数も、同じ実装箇所において2つのパラメーター「shallow_out・deep_out」で設定されていますが、こちらはいずれのBackboneも共通した値「shallow_out=256、deep_out=512」で設定されています。この場合のBase Featureのサイズは、2つのチャネル数をあわせた(768, 40, 40)となります。
※なお以降の行で(C, W, H)という表記は、チャネル数Cの解像度 (W x H) の特徴マップであることを表します。
FFMv2~TUMs
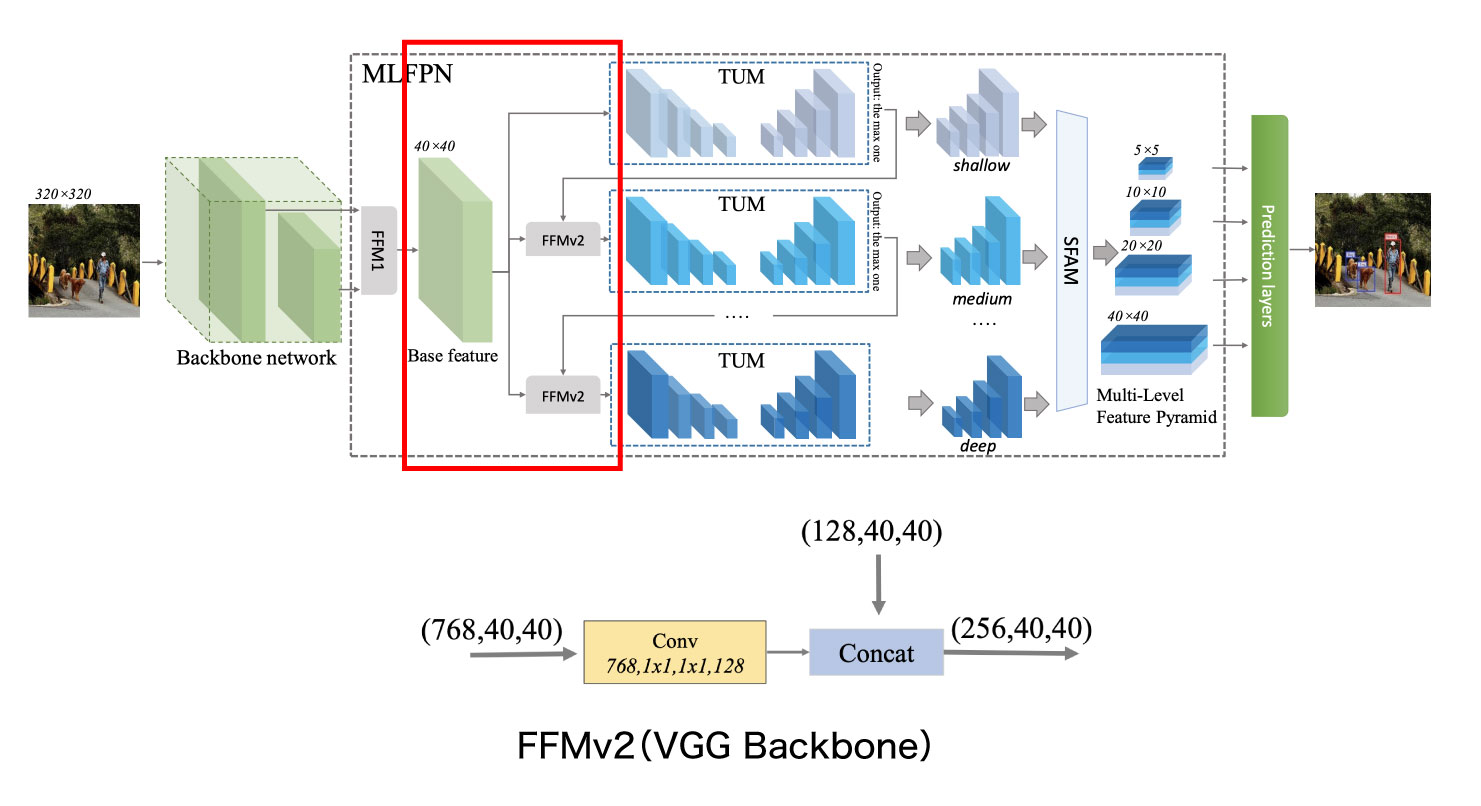
次にFFMv2について説明します。ここではFFMv1で作成されたBaseFeatureをThinned U-shape Modules(TUMs)に繋ぐ処理を行います(図5)。
具体的には、まずBase Feature (768, 40, 40) を畳み込み層に通し、チャネルを圧縮して(128, 40, 40)のサイズに変換します。これを直前のTUMが出力する複数サイズの特徴マップ(具体的な処理は後述)のうち、サイズが最も大きな(128, 40, 40)と結合し、特徴マップ(256, 40, 40)を生成して、次のTUMへ渡します。ただし最初のTUMには直前のTUMが存在しないため、FFMv2は使わず、チャネルを圧縮したBase Feature (128, 40, 40)だけが渡されます。なお著者実装上ではFFMという単語は出ておらず、また前半のConvolution部分と後半のConcat計算部分が別々になっています。
TUMはダウンサンプリングとアップサンプリングを行う複数の層から構成されます(図6)。論文では特定の名前がついていませんが、以下ではこの層を”U-shape Layer”と呼ぶことにします。
TUMの数は、著者実装においては「num_levels」という名前でconfigファイルにおいて8と設定されています(configs/m2det320_vgg.py 11行目)。個々のTUMの深さ(U-shape Layerにおける同じサイズのconvolution層-deconvolution層ペアの数)は同じく「num_scales」という名前でconfigファイルに6と設定されています(configs/m2det320_vgg.py 12行目)。これらについては論文通りの設定値です。
なお、論文中ではTUMの数(=「num_levels」)と各TUMのチャネルサイズ(=著者実装の「input_planes」)の各パラメーターがモデルのmAPへ与える影響度合いについて比較検証が行われています(表3)。詳細は割愛しますが、論文中の結果からはTUMおよびチャネルサイズの数を増やすごとに少しだけ精度が上がっています。ただし実際に利用する場合はメモリサイズや学習・推論時間にも影響するパラメータの数との兼ね合いでTUMの値を決めるのが良いでしょう。

下図7はnum_scalesが6の場合のTUMの構造を示したものですが、ご覧の通り論文に掲載されているアーキテクチャ図と、GitHub上で公開されているソースコードに実装されているアーキテクチャやアルゴリズムは少し異なる部分があります。この点は論文の著者自身がgithub issues#36 にも投稿しています。
TUM部分の論文とソースコードでの相違点は以下の2点です。
①TUMsの処理アーキテクチャ全般
②アップサンプリングを行う際に使用されているアルゴリズム
まず、①アーキテクチャの相違点について解説します。概要を図にすると以下のようになります。

上図7の下側にあるGitHub側の構成図は筆者が作成したものですが、これを作成するために参照しているソースコードの箇所が layers/nn_utils.py 26-98行目, m2det.py 46-62行目, 同 116-122行目です。
次に、「② アップサンプリングを行う際に使用されているアルゴリズム」の違いについてです。論文中ではアップサンプリングを行う際にはバイリニア補間を使うと書かれていますが、GitHubのソースコードでは最近傍法を使用して実装されています。オリジナルの論文で使われているバイリニア補間の実装コードはgithub issues#18の投稿中で著者が説明しています。2つの実装方法が下記図8になります。
▼論文の実装を再現したもの

▼GitHub上で公開されているソースコード

上記のように、論文とソースコードで処理の仕組み全体がやや異なっているため、実装を検討される際はこれらの点に注意して進めるようにしてください。
M2Det SFAM
SFAMの処理について説明します。
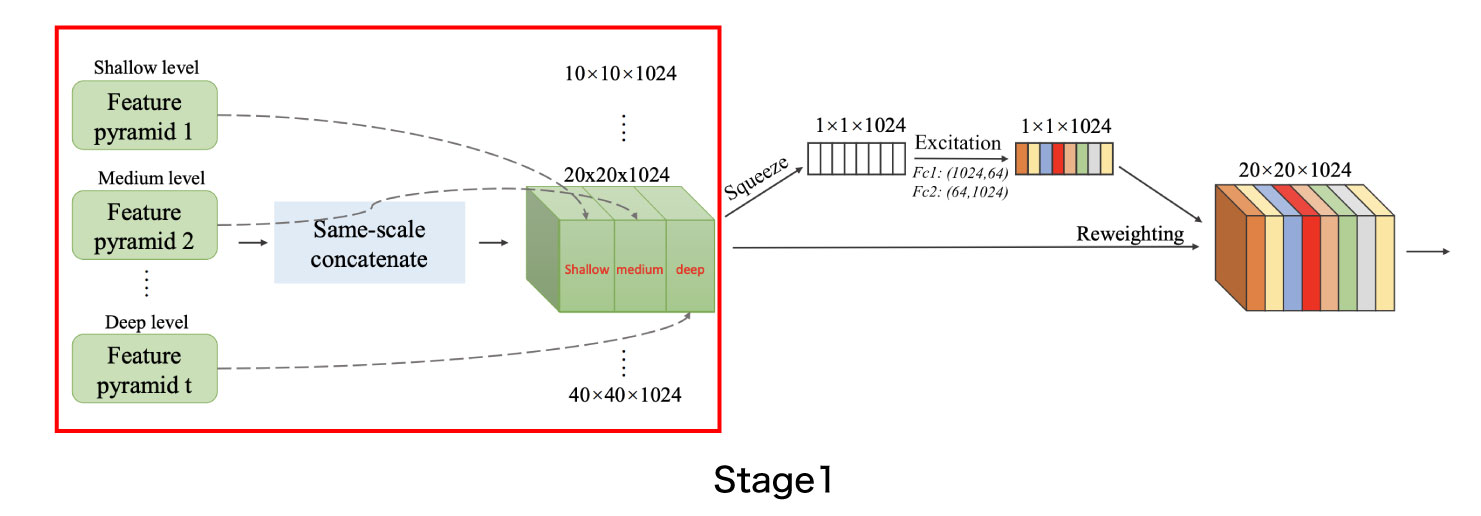
M2DetのScale-wise Feature Aggregation Module(SFAM) は各TUMの出力を統合してprediction Layerで推論処理をできるように整形するモジュールです(図9)。SFAMは主に2つのステージに分かれています。Stage1では、TUM間の出力を同じ大きさごとに結合して新たな特徴マップを作成します。前のセクションで説明した例の場合には、各TUMが6種類のサイズの特徴マップを出力するため、Stage1の出力で6つの特徴マップが得られます。Stage2では、SE (Squeeze-and-Excitation) によるAttention 機構を用いて、Stage1で結合された特徴マップを重み付けします。
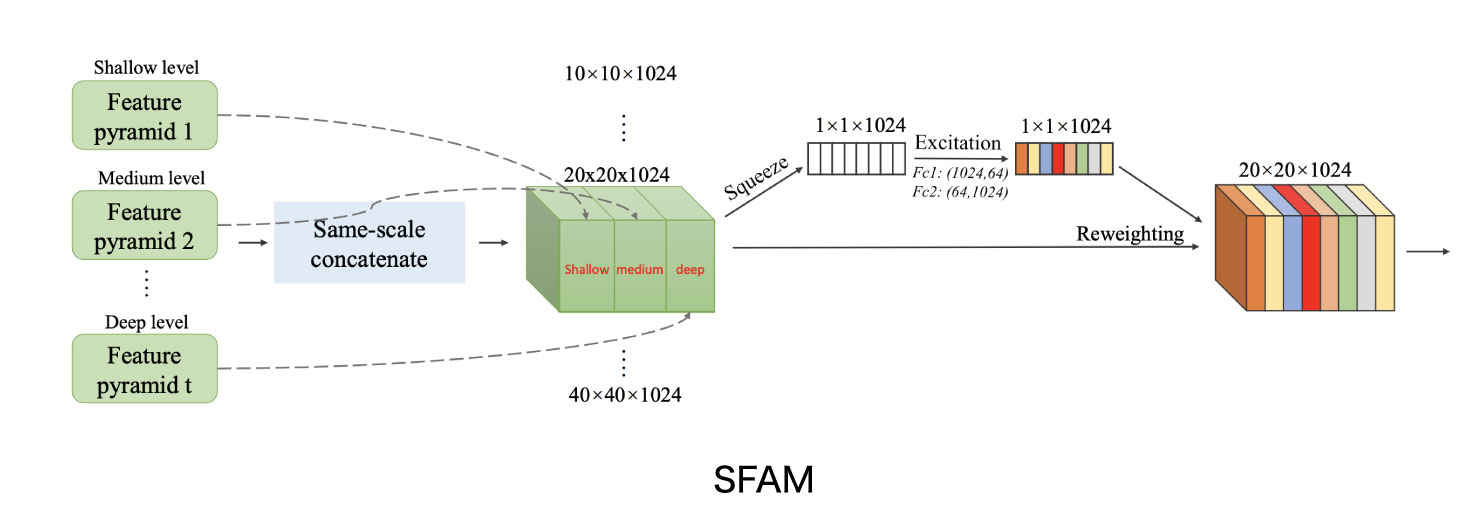
図9のアーキテクチャのうち、Stage1は図10で示している部分で、m2det.py 124行目のような実装となっています。
一方、Stage2のアーキテクチャは下図11に示しています。論文上ではStage1とStage2をあわせてSFAMと説明されていますが、ソースコードではStage2の部分のみがSFAMクラスとして実装されています( layers/nn_utils.py 133-160行目 )。なお、こちらもGithub上のソースコードと論文に記載されている説明図とでは設定値が少し異なっています。具体的には、結合した特徴マップのチャネル数が論文とソースコードで異なっており、論文では1024であるもののソースコード上のチャネル数は2倍の2048となっています。そのためSqueeze-and-Excitation で用いるFc1,Fc2のサイズも同じくそれぞれ論文の2倍のサイズである(2048,128), (128,2048)となります。
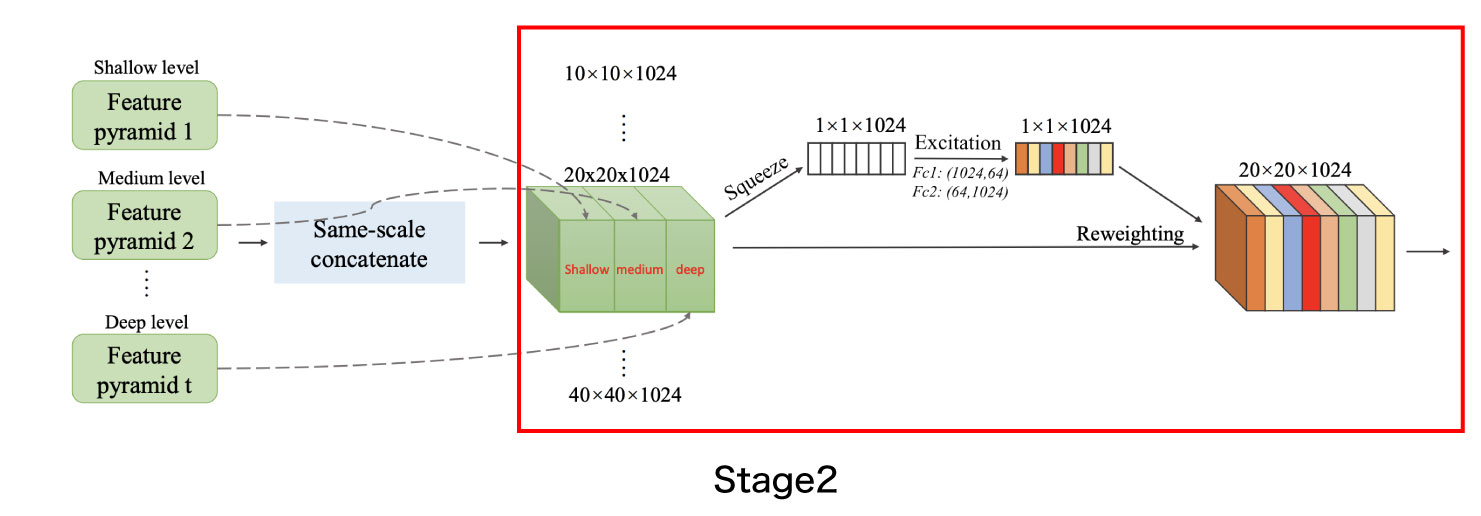
SFAMのパラメーターについても、図10で示したconfigファイルから設定できます。Github上にある「conifgs/m2det320_vgg.py」などのconfigファイルでは「sfam=False」という値がデフォルトで設定されていますが(図10参照)、この「sfam=False」という設定のままだとStage1までしか実行されず、Stage2の処理を経ないoutputが出力されます。論文で図示されている通りの処理を流すためには「sfam」の値をtrueに変更する必要がありますが、なぜFalseがデフォルト値として設定されているかはどこにも説明されていないため、この部分についてはどちらが正解なのかやや不透明です。
M2DetのPrediction Layer
SFAMの結果として得られた特徴マップからモデルの最終的な出力結果である対象の推論を行うPredictionレイヤーの説明します。
M2DetのPredictionレイヤーの仕組みはSSDのdefault box (ssd.pytorchではPriorBoxという名前)の仕組みが再利用されています。SFAMの出力である各スケールの特徴マップに対して、特徴マップ上の各セル毎に3種類のアスペクト比(1:1, 1:2, 1:3)からなる6種類のanchor boxを作成します。最終的に、SFAMの特徴マップのチャネル数を入力とし、各anchor boxに対応する位置情報(計24個)および確信度(計6個)を出力チャネル数とする2種類のConvolutionを行うことで対象の検出を行います。実際にはこの出力結果にNMS処理でフィルタリングしたものが最終結果になりますが、この部分はM2Detの後処理になるため、本コラムでは割愛します。
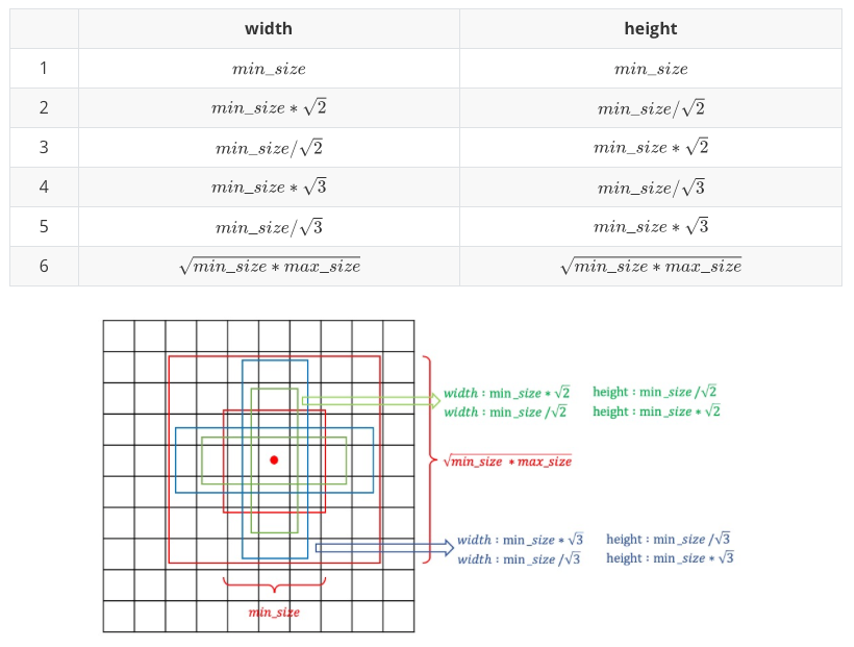
なお、anchor boxのサイズ定義はconfigファイルのanchor_configの設定値step_patternとsize_patternで行います( configs/m2det320_vgg.py 19-22行目 )。入力画像サイズ image_sizeとすると、i+1番目(i>=0)に大きなサイズの特徴マップで使用する6種類のanchor boxは、2つのパラメーターmin_size (= image_size * size_pattern[i]) と max_size (= image_size * size_pattern[i+1])に従って下図12の通りに作成されます
M2Det のLoss Function とLearning Rate
前章までがM2Detのネットワークの構成ですが、最後にM2Detにおける学習時のLossの扱い方と、論文で記載されているLearning Rate(学習率: 以下”LR”と表記)の内容を記載します。
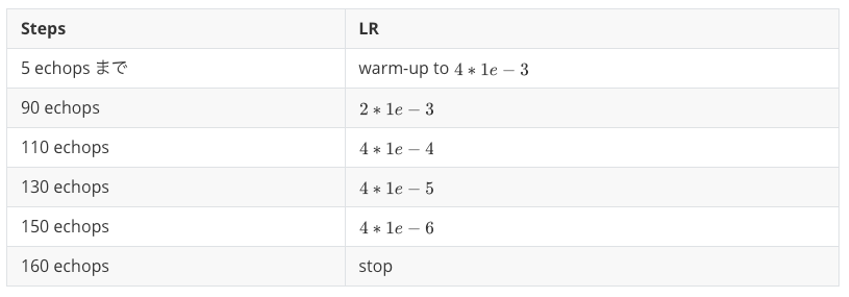
M2Det の Loss Functionは論文では全く触れられていませんが、著者実装ではSSDと同じものを使用しており、セクション3-1でも触れた ssd.pytorch パッケージに実装されているMultibox Lossを利用しています。詳細はリンク先を確認してください。M2Det のLRはstep decayを利用しています。論文のImplementation detailsセクション(図13)に書いてあるスケジュールでは、LRを最初5 epochs までwarm-upとし、その後に0.002に初期化されて、90 epochs と120 epochs の時にそれぞれ1/10に学習率を減衰し、150 epochsで学習を止めています。
著者実装では、configファイルに設定したLRの値をadjust_learning_rate関数で調整しています( configs/m2det320_vgg.py 31-37行目 および utils/core.py 71-84行目 )。なお、ここでもソースコードのLRスケジュールが論文上書いてあるものと異なっています。LRの値だけでなく、減衰も論文で書かれている倍の回数行われています。warm-upの方法については論文で触れられていませんでしたが、設定ファイルの”end_lr”の値より開始し、最終的にlr[0]の値になるようイテレーション1回毎に等間隔で増加させる実装になっています。
COCOデータセット に対して設定されたScheduleパラメーターを下記の表4にまとめました。
まとめ
M2Detは2019年の前半に発表され、最新最強の物体検出技術と呼ぶ人もいました。ただ、論文と著者が公開したソースコードの間に差異が大きく、COCOデータセットだけでなく、カスタマイズデータセットで再学習することが非常に難しい技術です(今回は詳細を割愛しますが、カスタマイズしたデータセットを使って弊社内で再学習したところ、非常に低い精度しか得られないという結果になりました)。カスタマイズデータでの学習が必要な場合、今回記載したソースコードの相違点などを再実装する必要があるため、実用的に利用するまでにそれなりの期間や手間がかかると考えるのが良いでしょう。
(KerasやTensorFlowで実装したケースも世の中の事例では存在しますが、今回は公開されているオリジナルのソースコードをベースに確認した結果を記載しています)。
コラム執筆者
機械学習エンジニア 胥 徳文
筑波大学大学院 システム情報工学研究科 博士前期課程修了。修士(工学)。卒業後、WEBシステム開発、スマホアプリ開発、及びプロジェクトマネジメントを経験し、組み込み系DeepLearning研究開発に従事した後、2019年6月よりLaboro.AIに参画。一般社団法人 日本ディープラーニング協会 E資格2019#1取得。



